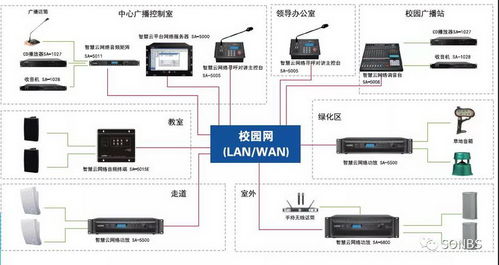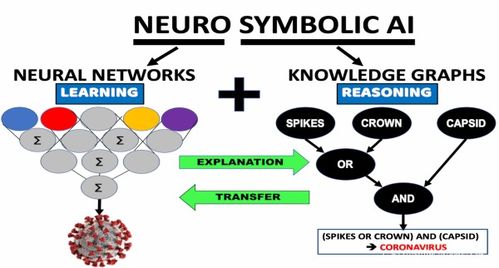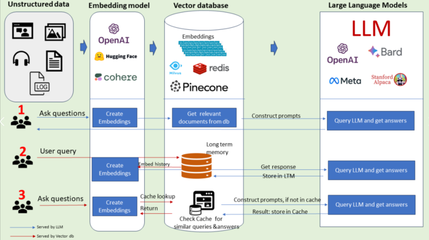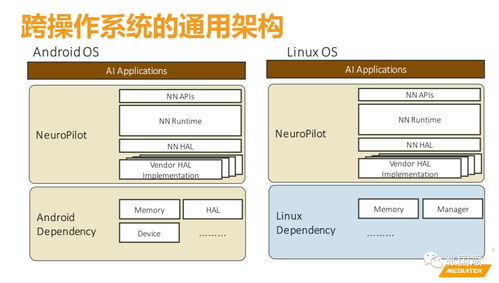
随着人工智能技术从实验室走向千行百业,作为其算力基石的人工智能芯片,已成为全球科技竞争的战略制高点。从训练巨量参数的“大模型”到执行具体任务的终端设备,不同场景对芯片的架构、能效和成本提出了迥异的要求。当前,产业格局呈现多元化竞争态势,既有英伟达凭借其CUDA生态在GPU领域构筑的深厚壁垒,也有谷歌TPU、华为昇腾等专用AI芯片的崛起,还有 Cerebras、Graphcore 等创业公司探索的颠覆性架构。
在追求“最强大脑”的征程中,衡量标准已不单纯是峰值算力。能效比、内存带宽、软件栈的易用性与丰富度、以及对特定算法(如Transformer)的优化程度,共同构成了核心竞争力。尤其是在人工智能通用应用系统的构建中,芯片需要具备高度的灵活性和可扩展性,以应对从云端训练到边缘推理,从视觉识别到自然语言处理等纷繁复杂的任务。
谁能成就支撑人工智能通用应用系统的“最强大脑”?答案可能并非唯一。一种观点认为,通过先进封装技术将不同功能的芯粒(Chiplet)集成,形成异构计算系统,是兼顾性能与灵活性的可行路径。另一种趋势是“软硬协同”的深度优化,即针对主流AI框架和算法,从芯片指令集层面进行定制设计。开源指令集RISC-V的兴起,也为AI芯片创新提供了新的底层架构选择,可能催生更多差异化的解决方案。
可以预见,人工智能芯片的竞争将是生态体系的全面较量。它不仅关乎硬件本身的性能,更依赖于整个软件工具链、开发者社区、应用场景的深度融合。那个能够以最高效率、最低成本赋能千行百业智能化转型的“最强大脑”,或许将诞生于最开放、最包容、最贴近实际需求的产业生态之中。这场关于算力王座的角逐,才刚刚进入精彩的中盘。